
April 2026
Agentic Engineering
The bigger the lever, the more your principles matter — axioms, observability, and fewer dependencies.
In the last months we saw a dramatic shift in the work culture - at least for many, myself included. For the most part I think it began with the hype of OpenClaw and the simple question "What happens if I am not the only Input to my Agent?" - since then the agentic usage of AI skyrocketed. Of course it also strongly correlated with the fact that models just got stronger and can do longer tasks, better planning and more consistent work all alone. I am still sure tho that with the right harness even smaller, not-almighty-seeming models do just fine - but for exploration and understanding the new reality it's of course easier to start with self healing super heroes like the current frontier models.
But enough introduction now - many of us in the tech industry might not have the time to explore and experiment with the new technology trend and just don't know where to start. As with every trend jumping on it after it started takes time, since you need to catch up with all the important concepts. Especially with the speedup our world is currently witnessing - boosted by immense capital and the capability of the new technology.
So I am here trying to answer your question of "How to agentic engineer in production?"
Since this article will touch many points I can not go into detail for every claim I am making otherwise you would read a book right now. So if you have any open questions after reading through feel free to contact me.
1. Leveraging into wrong directions
If you have a longer and stronger lever you can lift more weight with it, that's something humanity knew and used for a long time now. A longer and stronger lever means also you have the potential of creating more damage when using it wrong and unconsciously. Imagine you are working on Stonehenge and get distracted while being the lever controller, dropping the stone on your co workers - big upsie.
Now with AI we are all getting a bigger and stronger lever than we had before. It must feel similar to owning a car for the first time - one that is yours alone. Before, you were restricted by the time it takes you to walk or ride a bike to a certain destination. You were able to imagine where to go, but you could not because you just did not have the lever. But if you use the lever wrong - the car - then it's a lot easier to hurt yourself and others than by walking, since there is just more kinetic energy involved.
The same applies to AI - you can now reach goals which you could just imagine before. 2 years ago you might have thought "Imagine I could have an app that does X,Y and Z exactly like I want it to be!" - some programmer enthusiasts might have been born this way, but many might just have put their ideas to the side and said things like "that's impossible under my conditions", "I am not good enough" and so on. Now you can open either a low code platform or you can just subscribe to a frontier lab or any other platform which gives you access to the new lever and start. Remember the car analogy and the one about dropping stones? Now how strong is this lever you just got? Are you even conscious about all implications of your actions? Can you assume what happens when doing things wrong or unconscious? I hope so - for you, your company and your colleagues.
Now what I want to tell you is - yes AI makes things simpler and faster on the one side but to get competitive results you must earn your edge elsewhere right? Since anyone can produce code now the logical edge comes in composition, stability, scalability and orchestration. We are just shifting the mental model to something more abstract and that is by far not as easy as just writing some code. For earning the freedom of asking the right question and earning this competitive edge you must do the same things as you would need to do the old days - many principles still hold - and are even more important now due to the stronger lever. Implementing them becomes easier tho, at least with the right approach which I am going to show you now.
Solid — build on
Inverted — most apps
Most fancy apps focus on the UX - yes that's what's sellable and if you are a hobby project fine. I am addressing here companies not fun weekend projects. Many of us know that most people see only the tip of the iceberg and the visible tip must pay for all the layers below and that's a valid perspective. If you don't sell you can't have the iceberg at all. That's why fast prototyping starts with the inverse pyramid and that's why the inverse is so appealing to all of us - we just sell it quickly.
Application logic is separate from UX - some of you might want to merge it. At least in my taste, application logic is often independent from UX pages. And especially when you want to share logic (which still should be your goal even when generating code a lot faster with AI), it's most of the time mandatory at a certain scale.
Infrastructure and security is one block since security should be the result of infrastructure design - not something enforced by only application logic. Compare it to the design of the Stellarator - it is more complicated to build than a "normal" fusion reactor but it's easier to run stable since its design enforces the stability by default. We can also easily calculate this - just compare the additional expenses vs the saved cost per time unit. After a certain timepoint the initial input into the design will pay off.
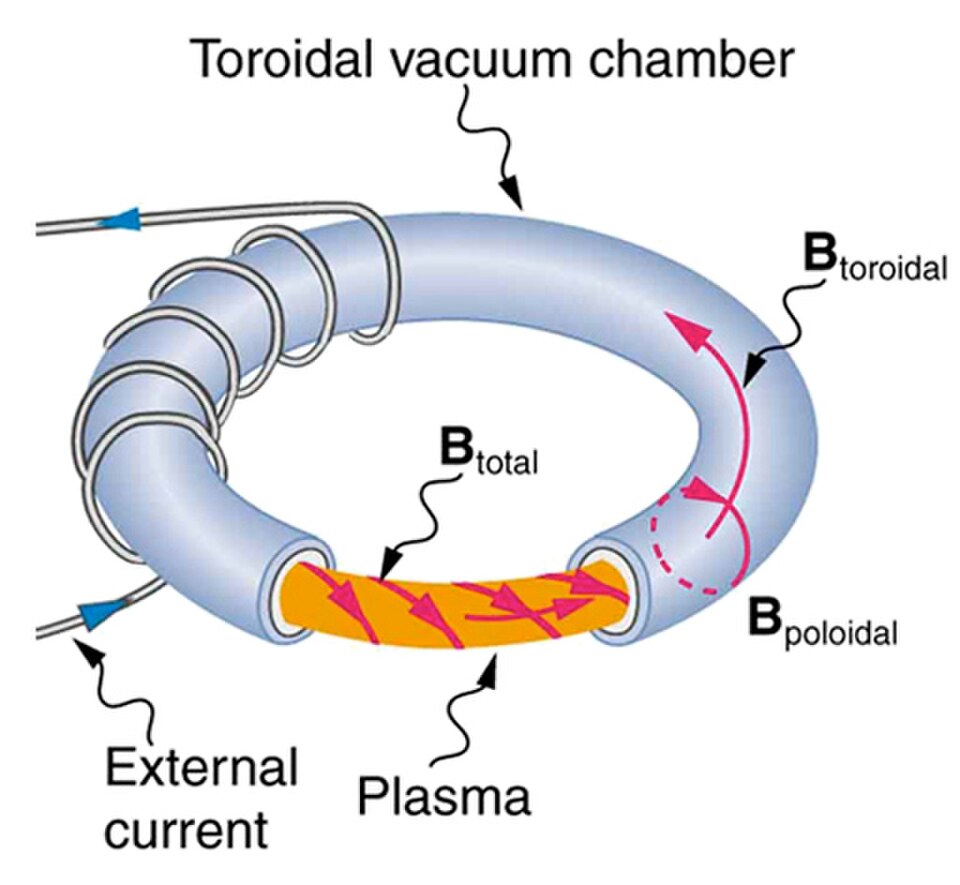
Tokamak — symmetric coils, hard to keep stable
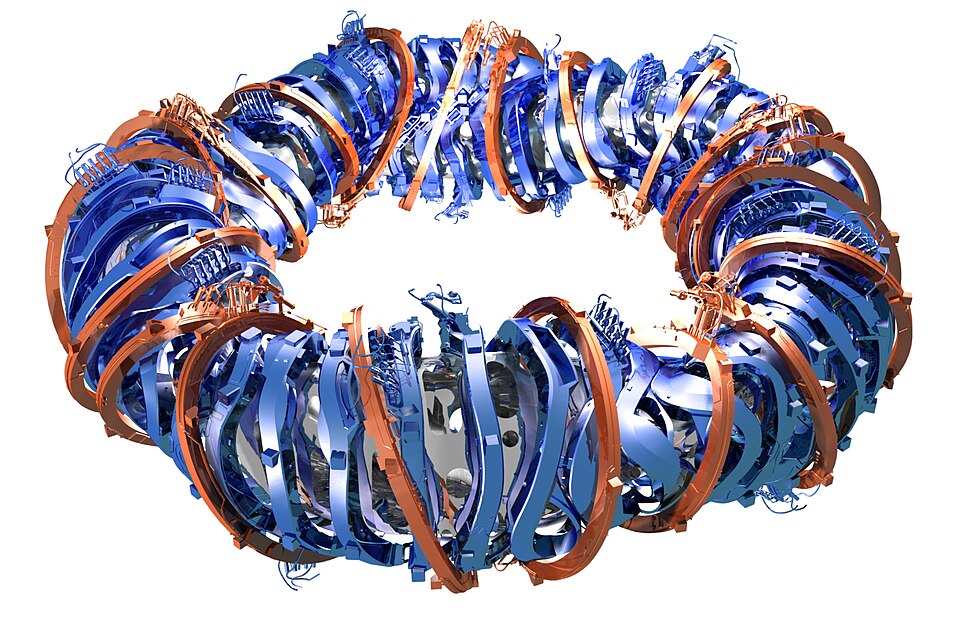
Stellarator — twisted by design, stable by default
Now a bold claim is the base - the axiomatic principles. By axiom I mean the mathematical sense: any proposition you reason from without proof. A chosen principle ("all decisions trace to a commit") and a chosen dependency ("Postgres behaves as documented") both qualify. Both are bets you have stopped re-litigating. Fewer bets, less surface to defend. I will not explain this exhaustively here, since this is worth its own article which will come soon. But the core concept is derived from the following - how many foundational rules do we need to describe our world today? Not many - a handful of foundational forces in physics and a handful of foundational axioms in mathematics are enough to create a perfectly valid picture of our observations. If you are just generating stuff and working additive you will never have clear foundational rules. Slowly but surely you will introduce scope creep and grow in both dimensions: functionality and implementation paths. If you have a tight basis of a few consistent rules which do not contradict each other you can scale a lot faster since you are preventing the mess which evolves out of mixing concerns and repeating yourselves in different ways. There will be more noise than signal which means from information theory perspective you will need to scream louder to be heard which then will introduce more additive clay on top of your already huge junk yard. In the next chapter I will teach you how to arrive there - and please do not misunderstand me here, it's not about restricting trial and error, it is about the decision what to keep and how to keep it. Exploration still is the most important path forward. Only thinking about problems does not solve them and without experimenting you will not have data to reason about each path.
2. Why - why?
Your strongest friend to come from the inverse fragile pyramid to the solid one is a single question which can't be repeated enough - why!

Most probably you are not starting on a green field ever - most of us are caught in a brownfield. And even new projects are already heavily biased by the environment they are starting in - so a fresh greenfield is most often more a promise and a dream than reality.
So let's say you are somewhere in between the 2 pyramid shapes. Assuming most of your team or all of your team is now using LLMs, they produce more code faster - which makes you struggle to review it under the current circumstances, since (as assumed) you do not have clean axiomatic rules yet which you can most of the time mechanically apply to it. This will make you drift more to the inverse pyramid especially when you are overseeing a team which works across different services or applications. At some points larger errors will surface and in most cases they will cost your company real money. There are already enough reported incidents and I bet those are the reasons for many of them.
The bad news - it will cost you time to find a clear way out.
The good news: there is a way out. And even better, you can use LLMs exceptionally well for this kind of work.
Start asking why. A lot more often and more rigorous. I hope you are just now asking yourself —
why?
Concretely: start to get all related documents within your reach. Make yourself a folder where you for now start collecting all related documents - or better a repository. The reality is 99% of us don't have the luxury of a clean monorepo or even having all information accessible in git. There are decisions and issues and documents spread across all kinds of apps. My tip: build yourself a repo and a pipeline which automatically keeps it fresh by requesting all important information. You will already profit by it just by seeing the changes day by day or week by week depending on your need for accuracy. And exactly this work is something you can easily do with an LLM in an afternoon. You don't need to fight against all different APIs - the LLM can read the docs and do the heavy lifting - you are there for the concept.
Once you have your information gathered you have half of the foundation of asking why, the other half is analyzing the information and extracting all patterns which can be found. Again we are humans which makes us extremely slow readers compared to LLMs - but guess what the strongest part of LLMs is? Pattern Matching! So spend some tokens to search through the pile of documentation and code and so on. Create clear statistics: how many concepts live in the code, how densely they are connected, how big the impact ratio of each is. There are many great articles out there about chunking code bases into vectors by using AST and other optimizations - but to start you can just rely on any frontier model and some python. Perfection can come once you have an established base. Don't overengineer before you even know what you are dealing with.
Now you have the preconditions to ask the whole question "why?". Now there are two types of persons: the one type which wants to start directly with the biggest chunk to achieve the maximum lever instantly. And the second kind which starts small to train the principle and increases step by step. And for this kind of work - please be the second kind. For 2 reasons - first, the most rarely occurring pattern is most likely also something which you can probably solve by something different. So take this concept and look at what gets solved by it. And second, it is lighter to train the concept of a "conscious why" on smaller chunks first - the blast radius is smaller. It is a bit like the Tower of Hanoi Game - with the twist that you start with a mixed pyramid.
For every piece you go through the chain of why's - and yes it is hard, we are conditioned from our environment, from brands, from social media from all those influential factors in our lives, to sparingly ask a deep why. But when you take your first concept and you find you can reduce the friction by for example removing the redis deployment since your Postgres used as cache would be perfectly fine for your requirements - you reduced friction. And if you answer it differently - then write it down. The act of writing helps you to reflect once more and is a second harder layer than just thinking it through.
3. What?
Now we answered the question for the steps - but not the answer for the goal and what the desired state should look like. From the pyramid - which I would myself declare as an axiom - we can derive direct consequences - and directly train the "why" rigorously.
Principle 1
Principles must be trackable and they must be verifiable
Why? If principles are not trackable we can't verify them and if we can't verify them we can't detect any drifts away from them. Git is your friend here.
Principle 2
A causal chain — actio and reactio — through the whole lifecycle, from thought to production
Why? We can't measure what we can't see. We should not iterate on guesses. To avoid guessing we need information - not nothing and not noise. We can't decide what's noise if we have not experienced noise. Therefore we need to log and correlate centrally - this allows us to build up a traceable path from the commit that locks down the decision up to the log in production that tells us where to improve. Here for example the Grafana Stack works excellently for you.
Principle 3
As few axioms as possible — therefore as few outside systems as possible
Why? We must trust foreign software - especially the APIs whose code we can't read - when using it. And even when we use a linux distro as base image, use Postgres or other open source projects we will not be able to read and understand all code of it. Therefore we can assume that when we use something foreign then we must see it as an axiom. And one fundamental axiom of us is to have as few axioms as possible to reduce cognitive friction. The good thing about this is it also automatically shrinks your attack surface since you may introduce fewer different systems.
As Bruce Lee said — I am not afraid of the man who can do 10.000 kicks, I am afraid of the man who trained 1 kick 10.000 times.
For example try to use one database provider and first think thoroughly whether you could measure worse performance or risk hard-failing consequences if you don't introduce a second different technology.
Those are some examples of what this procedure buys you. I leave it here for you as inspiration to start on your own stack - step by step.
Conclusion
The world is speeding up. The work is changing. The work is not getting less.
The mechanical burden drops - you are no longer limited by how fast you can type. We are now limited by how strictly we are able to apply principles and enforce the "Why" question. The mechanical flow of hacking goes away and gets replaced by silent thinking. And in principle the chain is simple —

- Fewer Axioms
- →
- Less Friction
- →
- Fewer Errors
- →
- More Parallelism
- →
- Faster Growing
- →
- Higher quality Output
An inspiring person once told me "Simplicity is the highest sophistication" — and I think we can learn this from nature in every corner. We just need to learn again to silently sit down, observe and think.
It is a hard process - and it requires training, daily. Feel free to contact us - we are interested in your thoughts and ready to help you by asking the right whys.
Need help in this fast-moving world?
Aquilo can help you in all kinds of situations — feel free to request a meeting with us.
Stay in the loop
Occasional notes on alignment, software, and how we build at Aquilo. No spam, unsubscribe anytime.
By subscribing you agree we may send you our newsletter. You can unsubscribe with one click from any email.
Was this useful?